Redis base info
Більшість людей думають, що Redis призначений лише для кешування.
Але він може набагато більше. Redis добре підходить для:
- Сховища сесій
- Розподіленого блокування
- Лічильників
- Обмежувача швидкості
- Рейтингу/таблиці лідерів
- Черги повідомлень
- тощо.
Redis (REmote DIctionary Server) - це нереляційна високопродуктивна СУБД. Швидке сховище даних у пам'яті з відкритим вихідним кодом для використання як бази даних, кешу, брокера повідомлень або черги. Redis зберігає всі дані в пам'яті, доступ до даних здійснюється тільки за ключем. Опціонально копія даних може зберігатися на диску. Цей підхід забезпечує продуктивність, що в десятки разів перевершує продуктивність реляційних СУБД, а також спрощує шардинг даних.
Цікава особливість Redis полягає в тому, що це - однопотоковий сервер. Таке рішення сильно спрощує підтримку коду, забезпечує атомарність операцій і дає змогу запустити по одному процесу Redis на кожне ядро процесора. Зрозуміло, кожен процес буде �прослуховувати свій порт. Рішення нетипове, але цілком виправдане, оскільки на виконання однієї операції Redis витрачає мало часу - близько однієї стотисячної секунди
Типи даних
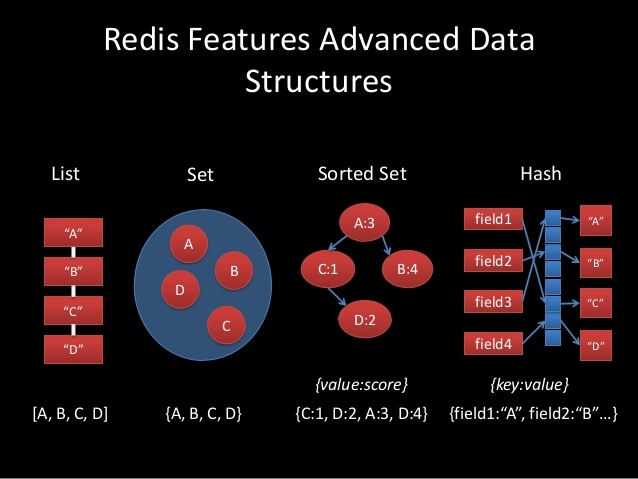
Рядки (strings)
Базовий тип даних Redis. Рядки в Redis бінарно-безпечні, можуть використовуватися так само як числа, обмежені розміром 512 Мб. Рядки - це основна структура. Це одна з чотирьох базових структур, а також основа всіх складних структур, тому що Список - це список рядків, Множина - це безліч рядків і так далі.
Рядки хороші у всіх очевидних сценаріях використання, коли ви хочете зберігати HTML-сторінку, але так само вони хороші, якщо ви хочете уникнути конвертації вже закодованих даних. Наприклад, якщо у вас є JSON або MessagePack, ви можете просто зберігати об'єкти як рядки. У Redis 2.6 ви навіть можете керувати цим видом структур на стороні �сервера, використовуючи скрипти на Lua.
Інше цікаве використання рядків - це бітові масиви, і взагалі, випадковий доступ до масивів байтів, оскільки Redis надає команди доступу до довільних діапазонів байтів, або навіть до окремих бітів.
Списки (lists)
Класичні списки рядків, упорядковані в порядку вставки, яка можлива як з боку голови, так і з боку хвоста списку. Максимальна кількість елементів - 2^32 - 1. Списки хороші коли в основному ви працюєте з крайніми елементами: біля хвоста, або біля голови. Списки не найкращий вибір для поділу чого-небудь на сторінки, через повільний випадковий доступ, O(N). Хорошим використанням списків будуть прості черги й стеки, або циклічна обробка елементів командою RPOPLPUSH, параметрами якої буде один і той самий список. Списки так само гарні, коли нам потрібна обмежена колекція з N елементів, доступ до якої зазвичай здійснюється тільки до верхнього або нижнього елементів, або коли N невелике.
Множини (sets)
Множини рядків у математичному розумінні: не впорядковані, підтримують операції вставки, перевірки входження елемента, перетину і різниці множин. Максимальна кількість елементів - 2^32 - 1. Множина - це не впорядкований набір даних, вона ефективна, коли ви маєте колекцію елементів, і важливо дуже швидко перевірити наявність елемента в колекції, або отримати її розмір. Ще одна "фішка" множин - це можливість отримати випадковий елемент.
Множини підтримують складні операції, як-от перетин, об'єднання тощо, це гарний спосіб використовувати Redis в "обчислювальній" манері, коли у вас є дані, і ви хочете отримати певний результат, виконуючи перетворення над цими даними. Невеликі множини кодуються дуже ефективним способом.
Множини використовуються для зберігання унікальних значень і надають набір операцій - таких, як об'єднання. Множини не впорядковані, але надають ефективні операції зі значеннями. Список друзів є класичним �прикладом використання множин:
sadd friends:leto ghanima paul chani jessica
sadd friends:duncan paul jessica alia
Незалежно від того, скільки друзів має користувач, ми можемо ефективно (O(1)) визначити, чи є користувачі userX і userY друзями, чи ні.
sismember friends:leto jessica
sismember friends:leto vladimir
Ба більше, ми можемо дізнатися, чи мають два користувачі спільних друзів:
sinter friends:leto friends:duncan
і навіть зберегти результат цієї операції під новим ключем:
sinterstore friends:leto_duncan friends:leto friends:duncan
Множини чудово підходять для теггінгу та відстеження будь-яких інших властивостей, для яких повтори не мають сенсу (або
там, де ми хочемо використовувати операції над множинами, як-от перетин і об'єднання).
Упорядковані множини (sorted sets)
Упорядкована множина відрізняється від звичайної тим, що її елементи впорядковані за особливим параметром "score". Упорядкована Множина - це єдина структура даних, крім списку, що підтримує роботу з упорядкованими елементами. З упорядкованими множинами можна робити багато крутих речей. Наприклад, ви можете реалізувати всі види Топу Чого-небудь у вашому вебдодатку. Топ користувачів за рейтингом, топ постів за кількістю переглядів, топ чого завгодно, і один екземпляр Redis буде обслуговувати тонни вставок і запитів на секунду.
Упорядковані множини, як і звичайні множини, можуть бути використані для опису відносин, але вони так само дадуть змогу ділити елементи на сторінки, і зберігати порядок. Наприклад, якщо я зберігаю друзів користувача X як впорядковану множину, я можу легко зберігати їх у порядку додавання в друзі.
Упорядковані множини гарні для черг із пріоритетами.
Упорядковані множини - це щось на зразок потужніших списків, у яких вставка, видалення або отримання елементів із середини списку так само швидко. Але вони використовують більше пам'яті, і є O(log(N)) структурами.
Упорядковані множини - симбіоз звичайних множин і списків. Річ у тім, що вони містять тільки унікальні значення, але кожному значенню відповідають число (score). У результаті для цього типу даних вводиться порядок:
A > B, якщо A.score > B.score, якщо A.score = B.score, то A і B упорядковуються відповідно до лексикографічного порядку значень. Оскільки вони унікальні, рівність двох різних елементів в упорядкованій множині неможлива.
Хеш-таблиці (hashes)
Хеш-таблиці (hashes). Класичні хеш-таблиці або асоціативні масиви. Максимальна кількість пар "ключ-значення" - 2^32 - 1. Хеші чудова структура для представлення об'єктів, складених із полів і значень. Поля хешів можуть бути атомарно інкрементовані командою HINCRBY. Якщо у вас є об'єкти, як-от користувачі, записи в блозі, або інші види елементів, хеші - це те, що вам потрібно, якщо ви не хочете використовувати свій власний формат, як-от JSON або будь-який інший.
Хеші - хороший приклад того, чому називати Redis сховищем пар ключ-значення не зовсім коректно. Хеші багато в чому схожі на рядки. Важливою відмінністю є те, що вони надають додатковий рівень адресації даних - поля (fields). Еквівалентами команд set і get для хешів є:
hset users:goku powerlevel 9000
hget users:goku powerlevel
Ми також можемо встановлювати значення одразу декількох полів, отримувати всі поля зі значеннями, виводити список усіх полів і видаляти окремі поля:
hmset users:goku race saiyan age 737
hmget users:goku race powerlevel
hgetall users:goku
hkeys users:goku
hdel users:goku age
Як ви бачите, хеші дають трохи більше контролю, ніж рядки. Замість того щоб зберігати дані про користувача у вигляді одного серіалізованого значення, ми можемо використовувати хеш для точнішого представлення. Перевагою буде можливість вилучення, зміни та видалення окремих частин даних без необхідності читати і записувати все значення цілком. Однак, майте на увазі, що невеликі хеші в Redis кодуються дуже ефективно, і ви можете використовувати атомарні операції GET, SET або атомарно інкрементувати окреме поле з великою швидкістю.
Бітові карти (bitmaps)
Bitmaps - це не власне тип даних, а набір бітових операцій, визначених над типом String. Оскільки рядки - це двійкові безпеч�ні блоки, а їхня максимальна довжина - 512 Мб, у них можна встановити до 232 різних бітів. Бітові операції поділяються на дві групи: постійні одноразові бітові операції, як-от встановлення біта в 1 або 0, або отримання його значення, та операції над групами бітів, як-от підрахунок кількості встановлених бітів у заданому діапазоні бітів (підрахунок чисельності популяцій).
Однією з найбільших переваг бітових карт є те, що вони часто забезпечують надзвичайну економію місця під час зберігання інформації. Наприклад, у системі, де різні користувачі представлені інкрементованими ідентифікаторами користувачів, можна запам'ятати одну бітову інформацію (наприклад, про те, чи хоче користувач отримувати інформаційний бюлетень) про 4 мільярди користувачів, використовуючи лише 512 Мб пам'яті.
HyperLogLog
Redis має спеціальне сховище HyperLogLog. Воно дає змогу зберігати туди ключі, а потім отримувати кількість унікальних ключів у цьому сховищі. Обмеження в тому, що список збережених ключів дістати неможливо. Перевага в тому, що одне таке сховище займає всього 12 Кб, здатне зберігати 264 елементи й повертає результат із похибкою всього 0.8%.
Streams
Redis Stream - новий абстрактний тип даних, представлений у Redis з виходом версії 5.0 Концептуально Redis Stream - це List, у який ви можете додавати записи. Кожен запис має унікальний ідентифікатор. За замовчуванням ідентифікатор генерується автоматично і містить тимчасову мітку. Тому ви можете запитувати діапазони записів за часом або отримувати нові дані в міру їх надходження в потік, як Unix команда "tail -f" читає лог-файл і завмирає, очікуючи нових даних. Зверніть увагу, що потік можуть слухати одночасно кілька клієнтів, як багато "tail -f" процесів можуть одночасно читати файл, не конфліктуючи один з одним.
- Повідомлення доставляється одному клієнту. Перший заблокований читанням клієнт отримає дані першим.
- Клієнт повинен сам ініціювати операцію читання кожного повідомлення. List нічого не знає про клієнтів.
- Повідомленн�я зберігаються доти, доки їх хтось не зчитає або не видалить явно. Якщо ви налаштували Redis сервер, щоб він скидав дані на диск, то надійність системи різко зростає.
Псевдобагатоключові Запити
Типовою ситуацією, у яку ви потраплятимете, буде необхідність запитувати одне й те саме значення за різними ключами. Наприклад, ви можете хотіти отримати дані користувача за адресою електронної пошти (у разі, якщо користувач входить на сайт вперше) і за ідентифікатором (після входу користувача на сайт). Одним із жахливих рішень буде дублювання об'єкта у двох строкових значеннях:
set users:[email protected] "{id: 9001, email: '[email protected]', ...}"
set users:9001 "{id: 9001, email: '[email protected]', ...}"
Це неправильно, оскільки такими даними важко керувати, і вони займають удвічі більше пам'яті.
Було б чудово, якби Redis давав змогу створювати зв'язок між двома ключами, але такої можливості немає (і, найімовірніше, ніколи не буде). Головним принципом розвитку Redis є простота коду та API. Внутрішня реалізація пов'язаних ключів (є багато речей, які можна робити з ключами, про що ми ще не говорили) не варта можливих зусиль, якщо ми побачимо, що Redis вже надає рішення - хеші.
Використовуючи хеш, ми можемо позбутися необхідності дублювання:
set users:9001 "{id: 9001, email: [email protected], ...}"
hset users:lookup:email [email protected] 9001
Ми використовуємо поле як вторинний псевдоіндекс, і отримуємо посилання на єдиний об'єкт, що представляє користувача. Щоб отримати користувача за ідентифікатором, ми використовуємо звичайну команду get:
get users:9001
Щоб отримати користувача за адресою електронної пошти, ми скористаємося спочатку hget, а потім get (код на Ruby):
id = redis.hget('users:lookup:email', '[email protected]')
user = redis.get("users:#{id}")
Це те, чим ви, найімовірніше, будете користуватися дуже часто. Для мене це якраз той випадок, коли хеші особливо гарні, але це не очевидний спосіб використання, поки ви не побачите це на власні очі.
Зберігання
Redis зберігає дані в оперативній пам'яті, але періодично зберігає їх на диск, щоб відновити під час перезапуску. Стандартні налаштування зроблені для швидкості, а не надійності, тому під час перезапуску частина даних втрачається. Але є можливість писати дані на диск. Ціна - різка деградація продуктивності.
Є 4 режими:
- RDB (Redis Database): Персистенція RDB виконує точкові моментальні знімки вашого набору даних із заданими інтервалами.
- AOF (Append Only File): Персистенція AOF фіксує в лог-файлі кожну операцію запису, отриману сервером, яка відтворюватиметься під час запуску сервера, відновлюючи вихідний набір даних. Команди записуються в лог-файл у тому самому форматі, що і сам протокол Redis, тільки для додавання. Redis вміє перезаписувати лог у фоновому режимі, коли він стає занадто великим.
- Відсутність персистенції: За бажанням ви можете повністю відключити персистенцію, якщо хочете, щоб ваші дані існували доти, доки працює сервер.
- RDB + AOF: Можна об'єднати в одному екземплярі як AOF, так і RDB. Зауважте, що в такому разі при перезавантаженні Redis для відновлення вихідного набору даних буде використано файл AOF, оскільки він гарантовано є найбільш повним.
RDB-snapshot
Повний зліпок усіх даних. Встановлюється за допомогою конфігурації SAVE X Y і читається як "Зберігати повний снепшот усіх даних кожні X секунд, якщо змінилося хоча б Y ключів". Найпростіший спосіб робити резервні копії даних. Завдяки стисненню, які можна ввімкнути в конфігурації, займає набагато менше місця, ніж на диску AOF. Являє собою єдиний файл, який оновлюється періодично автоматично, якщо в конфігурації вказано параметр SAVE, або за необхідності за допомогою команд SAVE або BGSAVE.
RDB - це дуже компактне однофайлове представлення ваших даних Redis на певний момент часу. Файли RDB ідеально підходять для резервного копіювання. Наприклад, ви можете захотіти архівувати файли RDB щогодини протягом останніх 24 годин і зберігати моментальний знімок RDB щодня протягом 30 днів. Це дає змогу легко відновлювати різні версії набору даних у разі аварій.
RDB максимізує продуктивність Redis, оскільки єдина робота, яку повинен виконати батьківський процес Redis для збереження, - це розгалуження дочірнього процесу, який зробить все інше. Батьківський процес ніколи не буде виконувати дискове введення-виведення або щось подібне.
RDB дає змогу швидше перезапускати великі набори даних порівняно з AOF.
На репліках RDB підтримує часткову повторну синхронізацію після перезапуску і відпрацювання відмови.
Мінуси
RDB НЕ підходить, якщо вам потрібно звести до мінімуму ймовірність втрати даних у разі, якщо Redis перестане працювати (наприклад, після вимкнення електроенергії). Ви можете налаштувати різні точки збереження, у яких створюється RDB (наприклад, після щонайменше п'яти хвилин і 100 операцій запису в набір даних у вас може бути кілька точок збереження). Однак ви зазвичай створюєте моментальний знімок RDB кожні п'ять хвилин або частіше, тому в разі, якщо Redis перестане працювати без коректного завершення роботи з будь-якої причини, ви маєте бути готові втратити останні хвилини даних.
RDB необхідно часто виконувати fork(), щоб зберігатися на диску за допомогою дочірнього процесу. fork() може займати багато часу, якщо набір даних великий, і може призвести до того, що Redis перестане обслуговувати клієнтів на кілька мілісекунд або навіть на одну секунду, якщо набір даних дуже великий, а продуктивність процесора невисока. AOF також потребує fork(), але рідше, і ви можете налаштувати, як часто ви хочете переписувати свої журнали без будь-якого компромісу щодо довговічності.
AppendOnlyFile
Список операцій у порядку їх виконання. Додає нові операції, що надійшли, у файл кожні Х секунд або кожні Y операцій. Для AOF можна налаштувати політики fsync: щосекунди, на кожен запит або взагалі нічого не робити. Завдяки тому, що під час використання AOF Redis за замовчуванням пише дані на диск щосекунди, максимум, що ви втрачаєте в разі збою під час використання цього режиму - це 1 секунда. Redis може автоматично перезаписувати AOF-файл, якщо він стає занадто великим. Але в AOF теж є недоліки.
Зазвичай файли AOF набагато більші за розміром, ніж аналогічний файл RDB, за того ж набору даних. AOF може бути повільнішим, ніж RDB на запис, залежно від налаштувань fsync. Крім того, навіть у разі великого навантаження на запис RDB краще поводиться в плані затримок.
RDB+AOF
Комбінація двох попередніх.
У будь-якому разі Redis - не високонадійне сховище даних, а швидка легка база для даних, які нестрашно втратити.
TTL
Redis дає змогу призначати ключам термін існування. Ви можете використовувати абсолютні значення часу у форматі Unix (Unix timestamp, кількість секунд, що минули з 1 січня 1970 року) або час, що залишився для існування, у секундах. Ця команда оперує ключами, тому неважливо, яка структура даних при цьому використовується.
expire pages:about 30
expireat pages:about 1356933600
Перша команда видалить ключ (і асоційоване з ним значення) після закінчення 30 секунд. Друга зробить те ж саме о 12:00, 31 грудня 2012 року
За замовчуванням усі дані зберігаються вічно.
Транзакції
Як і все інше, реалізовані просто і забезпечують атомарне виконання набору команд. Ізоляції немає, але в Redis вона і не потрібна, оскільки Redis - однопотоковий додаток, і транзакції не виконуються паралельно.
Реплікація
Реалізована як master-slave: на master можна писати й читати, slave - тільки читання. Налаштовується легко, працює безвідмовно. Реплікація з кількома головними серверами не підтримується. Кожен підлеглий сервер може виступати в ролі головного для інших. Реплікація в Redis не призводить до блокувань ні на головному сервері, ні на підлег�лих. На репліках дозволена операція запису. Коли головний і підлеглий сервер відновлюють з'єднання після розриву, відбувається повна синхронізація (resync).
Redis підтримує реплікацію, яка означає, що всі дані, які потрапляють на один вузол Redis (який називається master) будуть потрапляти також і на інші вузли (називаються slave). Для конфігурування slave-вузлів можна змінити опцію slaveof або виконати аналогічну за написанням команду (вузли, запущені без подібних опцій, є master-вузлами).
Кожен хеш-слот має від 1 (master) до N (N-1 slave) реплік. Таким чином, якщо вийде з ладу деякий слот, то кластер призначить його slave master-ом.
Redis Cluster
Був доданий в Redis v.3.0, і є повноцінним native рішенням для створення і управління кластером із сегментацією і реплікацією даних. Виконує завдання управління нодами, реплікації, синхронізації даних, забезпеченням доступу до них у разі виходу з ладу одного або більше майстрів.
- Кілька майстер-інстансів, у кожного один або більше слейвів (до 1000).
- Виконує в�сі завдання з шардингу, реплікації, failover, синхронізації даних.
- Вимагає щонайменше 6 нод Reedis-а: три для майстрів і три для слейвів.
- Вміє перенаправляти запити від клієнтів на потрібний майстер або слейв - але це вимагає підтримки кластера самими клієнтами Redis.
Сегментація
Кластер не використовує консистентне хешування, натомість використовується так звані hash-slots. Весь кластер має 16384 слотів, для обчислення хеш-слота для ключа використовується формула crc16(key) % 16384. Кожен вузол Redis відповідає за конкретну підмножину хеш-слотів, наприклад:
- Вузол A містить хеш-слоти від 0 до 5500.
- Вузол B містить хеш-слоти від 5501 до 11000.
- Вузол C містить хеш-слоти від 11001 до 16383.
Це дає змогу легко додавати і видаляти вузли кластера. Якщо ми додаємо вузол D, то можна просто перемістити деякі хеш-лоти інших вузлів. Якщо ж видаляємо A, то нам необхідно поступово перемістити всі хеш-слоти вузла А на інші, а коли хеш-слотів не залишиться, то просто ви�далити вузол із кластера. Усе це виконується поступово командами, нам не потрібно припиняти виконання операцій, не потрібно перераховувати відсоткове співвідношення хеш-слотів до кількості вузлів, жодних інших зупинок системи.
Виникає питання - Redis має складні структури даних зі складовими ключами, адже хеш-функція порахує для них різні значення? Є і відповідь:
- Складові ключі однієї команди, однієї транзакції або одного скрипту Lua гарантовано потраплять в один хеш-слот.
- Користувач може примусово зробити складові ключі частиною одного хеш-слота за допомогою концепту хеш-тегів.
Якщо коротко, то хеш-теги кажуть Redis що саме хешувати, мета хешування задається у фігурних дужках. Так, хеші цих ключів дорівнюватимуть - foo.key.bar і baz.key.biz.